deep learning
http://www.technologyreview.com/featuredstory/513696/deep-learning/
2013
Deep-learning software attempts to mimic the activity in layers of neurons in the neocortex, the wrinkly 80 percent of the brain where thinking occurs. The software learns, in a very real sense, to recognize patterns in digital representations of sounds, images, and other data.
The basic idea—that software can simulate the neocortex’s large array of neurons in an artificial “neural network”—is decades old, and it has led to as many disappointments as breakthroughs. But because of improvements in mathematical formulas and increasingly powerful computers, computer scientists can now model many more layers of virtual neurons than ever before.
Google also used the technology to cut the error rate on speech recognition in its latest Android mobile software.
app/chip update ideas – where data focus is on self-talk – to ground chaos (and facilitate deep learning) of 7 billion people set free to do what they were meant to do..
[..]
Programmers would train a neural network to detect an object or phoneme by blitzing the network with digitized versions of images containing those objects or sound waves containing those phonemes. If the network didn’t accurately recognize a particular pattern, an algorithm would adjust the weights. The eventual goal of this training was to get the network to consistently recognize the patterns in speech or sets of images that we humans know as, say, the phoneme “d” or the image of a dog. This is much the same way a child learns what a dog is by noticing the details of head shape, behavior, and the like in furry, barking animals that other people call dogs.
[..]
In 2006, Hinton developed a more efficient way to teach individual layers of neurons. The first layer learns primitive features, like an edge in an image or the tiniest unit of speech sound. It does this by finding combinations of digitized pixels or sound waves that occur more often than they should by chance. Once that layer accurately recognizes those features, they’re fed to the next layer, which trains itself to recognize more complex features, like a corner or a combination of speech sounds. The process is repeated in successive layers until the system can reliably recognize phonemes or objects.
[..]
There’s more to it than the sheer size of Google’s data centers, though. Deep learning has also benefited from the company’s method of splitting computing tasks among many machines so they can be done much more quickly. That’s a technology Dean helped develop earlier in his 14-year career at Google. It vastly speeds up the training of deep-learning neural networks as well, enabling Google to run larger networks and feed a lot more data to them.
yeah. so this sounds like school. and factory work. no? let’s let tech do that.
let’s humans do thing things we can’t not do… in the city. as the day.
Already, deep learning has improved voice search on smartphones. Until last year, Google’s Android software used a method that misunderstood many words. But in preparation for a new release of Android last July, Dean and his team helped replace part of the speech system with one based on deep learning. Because the multiple layers of neurons allow for more precise training on the many variants of a sound, the system can recognize scraps of sound more reliably, especially in noisy environments such as subway platforms. Since it’s likelier to understand what was actually uttered, the result it returns is likelier to be accurate as well. Almost overnight, the number of errors fell by up to 25 percent—results so good that many reviewers now deem Android’s voice search smarter than Apple’s more famous Siri voice assistant.
perfect timing. democratizing access.. to equity. no?
[..]
For now, Kurzweil aims to help computers understand and even speak in natural language. “My mandate is to give computers enough understanding of natural language to do useful things—do a better job of search, do a better job of answering questions,” he says.
so this would truly be human and machine learning from one another.. the more we talk – the more it learns natural language. the more it learns natural language.. the better it finds us daily matches. help us get toward no words needed.. and/or beyond words…[not to mention us just getting more eudaimonious from talking in an echo chamber – a space w/no judgment… only listening..documenting..]
[..]
deep learning is likely to spur other applications beyond speech and image recognition in the nearer term. For one, there’s drug discovery. The surprise victory by Hinton’s group in the Merck contest clearly showed the utility of deep learning in a field where few had expected it to make an impact.
imagine it goes beyond that… ie: facilitating free people’s curiosities.. so that less drugs are even needed.
______

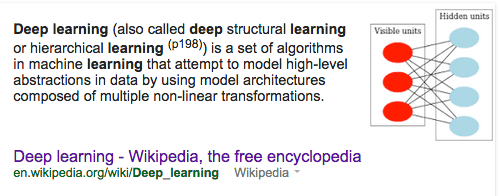
Deep learning (also called deep structural learning or hierarchical learning) is a set of algorithms in machine learning that attempt to model high-level abstractions in data by using model architectures composed of multiple non-linear transformations.
Deep learning is part of a broader family of machine learning methods based on learning representations of data. An observation (e.g., an image) can be represented in many ways (e.g., a vector of intensity values, one per pixel), but some representations make it easier to learn tasks of interest (e.g., is this the image of a human face?) from examples, and research in this area attempts to define what makes better representations and how to create models to learn these representations.
Various deep learning architectures such as deep neural networks, convolutional deep neural networks, and deep belief networks have been applied to fields likecomputer vision, automatic speech recognition, natural language processing, and music/audio signal recognition where they have been shown to produce state-of-the-art results on various tasks.
Alternatively, “deep learning” has been characterized as “just a buzzword for”, or “largely a rebranding of”, neural networks.
Deep learning in the human brain
Computational deep learning is closely related to a class of theories of brain development (specifically, neocortical development) proposed by cognitive neuroscientists in the early 1990s. An approachable summary of this work is Elman, et al.’s 1996 book “Rethinking Innateness” (see also: Shrager and Johnson; Quartz and Sejnowski ). As these theories were also instantiated in computational models, they are technical predecessors of purely computationally-motivated deep learning models. These models share the interesting property that various proposed learning dynamics in the brain (e.g., a wave of nerve growth factor) conspire to support the self-organization of just the sort of inter-related neural networks utilized in the later, purely computational deep learning models, and which appear to be analogous to one way of understanding the neocortex of the brain as a hierarchy of filters where each layer captures some of the information in the operating environment, and then passes the remainder, as well as modified base signal, to other layers further up the hierarchy. The result of this process is a self-organizing stack of transducers, well-tuned to their operating environment. As described in The New York Times in 1995: “…the infant’s brain seems to organize itself under the influence of waves of so-called trophic-factors … different regions of the brain become connected sequentially, with one layer of tissue maturing before another and so on until the whole brain is mature.”
a self-organizing stack of transducers, well-tuned to their operating environment.
The importance of deep learning with respect to the evolution and development of human cognition did not escape the attention of these researchers. One aspect of human development that distinguishes us from our nearest primate neighbors may be changes in the timing of development. Among primates, the human brain remains relatively plastic until late in the post-natal period, whereas the brains of our closest relatives are more completely formed by birth. Thus, humans have greater access to the complex experiences afforded by being out in the world during the most formative period of brain development. This may enable us to “tune in” to rapidly changing features of the environment that other animals, more constrained by evolutionary structuring of their brains, are unable to take account of. To the extent that these changes are reflected in similar timing changes in hypothesized wave of cortical development, they may also lead to changes in the extraction of information from the stimulus environment during the early self-organization of the brain. Of course, along with this flexibility comes an extended period of immaturity, during which we are dependent upon our caretakers and our community for both support and training. The theory of deep learning therefore sees the coevolution of culture and cognition as a fundamental condition of human evolution.
Daniel Coyle ness
attachment longer rather than shorter..
______
added the page after watching Jeremy Howard‘s ted.
used the verbiage the last 5 yrs since i read the talent code.
thinking hierarchy (stigmergy-style) and stack/deep-address/haeccities ness of an art ist:
__________
Facebook Starts Auto-Enhancing Photos Because Algorithms Are Better At Filters Than You | TechCrunch http://t.co/yfTNaNsUdr
Original Tweet: https://twitter.com/loic/status/545085205321883648
____________
intro’d to this term – haeccities – by Benjmain Bratton via deep address:
Instead of the popular term, “the internet of things,” which implies a network of physical objects, Bratton prefers the more esoteric sounding, “internet of haeccities” which would include objects, but also concepts and memes, addressable at the same level, but at multiple scales, through the same system. “Scales blur and what seemed solid becomes fuzzy. Inevitably we see that any apparently solid scale is really only a temporary state of resolution.”
The bottom line, says Bratton:
the inherent intelligence of the world could be more self-reflexive in new and important ways.
commonplace book/non-linear portfolio,document everything ness ish..
a nother way (singularity) toward global systemic change.
_________
june 2015 – growing pains for deep learning.. shared on twitter by p omidyar:
http://m.cacm.acm.org/news/188737-growing-pains-for-deep-learning/fulltext
Yann LeCun, director of artificial intelligence research at Facebook and founding director of New York University’s Center for Data Science, says, “Before, neural networks were not breaking records for recognizing continuous speech; they were not big enough. When people replaced Gaussian models with deep neural nets, the error rates went way down.”
[..]
“We carry an additional algorithmic burden, that of propagating the uncertainty around the network,” Lawrence says. “This is where the algorithmic problems begin, but is also where we’ve had most of the breakthroughs.”


















